Storage Migration to the Cloud
From ad hoc data collection to a secure relational database on AWS
When I first began creating data-heavy reports for management, I had to consult multiple data sources from across departments. This was a grinding inefficiency in my workflow. Furthermore, sometimes I needed to work from home, which added another layer of difficulty to accessing data. I needed the data to be immediately available as soon as the research question dropped.
I needed a cloud database.
Creating a Database Instance
There are many options for low-cost relational databases in the cloud. Both Amazon Web Services and Microsoft Azure offer free 12 month trials, followed by data usage-based pricing plans.
To connect to my cloud database, I used MySQL Workbench. I just added a new connection, then entered the endpoint, port, username and password info. Within the AWS instance dashboard, I also needed to assign a security group to multiple IPs in order to allow access at both my home and office.
Storage Migration
Our office leases a CRM tool, Successware21, which has a SQL backend but a clunky userform-based front-end. Despite the SQL backend, Successware’s data was not tidy when exported to a .csv file. An R script was written to clean each file prior to writing to the RDBS. For especially messy datasets, Visual Basic in Excel was also used.
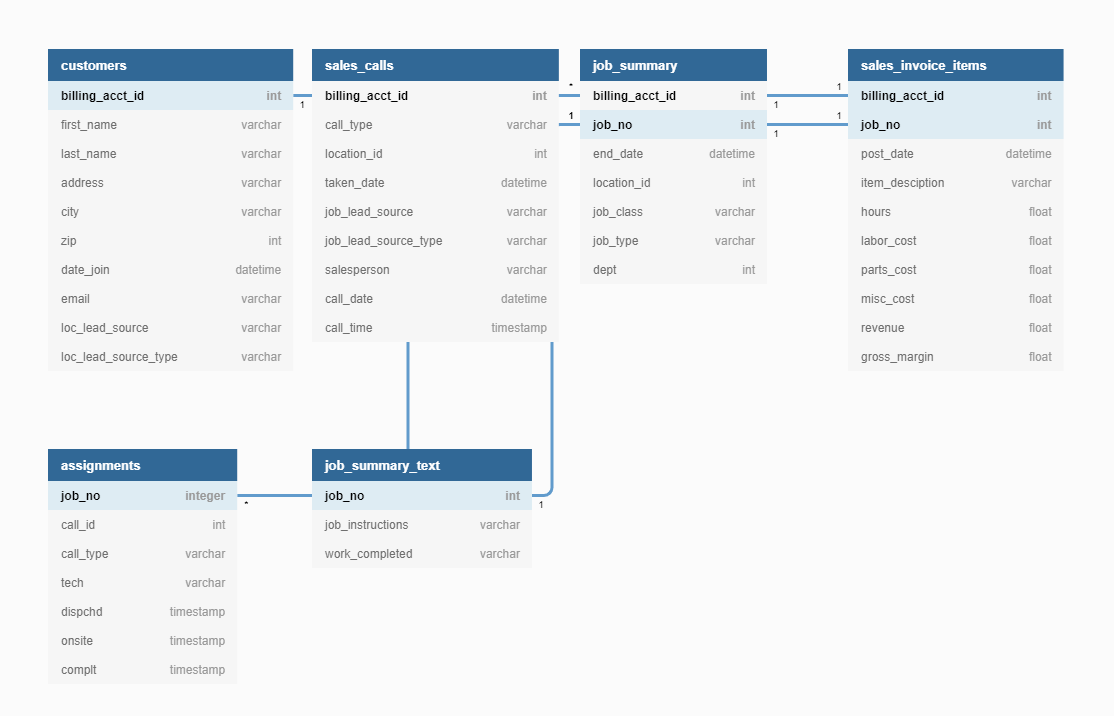
Database Model
In order to visualize the connections between the tables and variables, I created a database model using dbdiagram.io, which uses Database Markup Language (DBML) to structure the model from the command line.
Documentation
The process of exporting, cleaning and writing the data to the database is thoroughly documented in a Github repo.
The documentation consists of two parts: a “how-to” user guide for exporting data and references to project resources including the revision history, data dictionary (tables, columns, data types and values), SQL queries and more.
Maintenance
Finally, the database is ready to go. All that I need to do is update it on a regular basis.
Analytics
Whenever I have a research question, I can log into whatever analytics software I like and get to work.
In R Studio, I use either the DBI or RMariaDB packages to download my data. All it takes is a few lines of code:
library(RMariaDB)
con <- dbConnect(MariaDB(),
user = '[USERNAME]',
password = '[PASSWORD]',
host = '[INSTANCE_ENDPOINT]',
dbname='[SCHEMA]')
mydata <- dbReadTable(conn = con, name = '[TABLENAME]', value = [TABLENAME], overwrite = TRUE)
In a Jupyter Notebook running Python, I use the sqlalchemy module.
import sqlalchemy as db
connection_string = "mysql://[USERNAME]:[PASSWORD]@[ENDPOINT]:[PORT]/[SCHEMA]"
engine = db.create_engine(connection_string)
query = "select * from [TABLE]"
df = pd.read_sql_query(query, engine)
Wrapping Up
In the end, I’ve come to the conclusion that database administration and data analysis are like peanut butter and jelly: They’re both great on their own, but they taste even better together.